BIG-IP Configuration Conversion Scripts
Kirk Bauer, John Alam, and Pete White created a handful of perl and/or python scripts aimed at easing your migration from some of the “other guys” to BIG-IP.While they aren’t going to map every nook and cranny of the configurations to a BIG-IP feature, they will get you well along the way, taking out as much of the human error element as possible.Links to the codeshare articles below. Cisco ACE (perl) Cisco ACE via tmsh (perl) Cisco ACE (python) Cisco CSS (perl) Cisco CSS via tmsh (perl) Cisco CSM (perl) Citrix Netscaler (perl) Radware via tmsh (perl) Radware (python)1.6KViews1like13CommentsBIG-IP VE on Google Cloud Platform
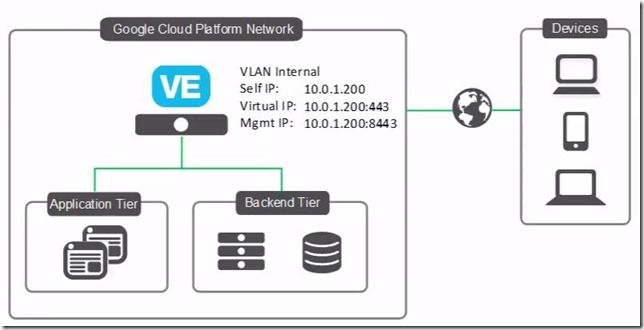
Hot off Cloud Month, let’s look at how to deploy BIG-IP Virtual Edition on the Google Cloud Platform. This is a simple single-NIC, single IP deployment, which means that both management traffic and data traffic are going through the same NIC and are accessible with the same IP address. Before you can create this deployment, you need a license from F5. You can also get a trial license here. Also, we're using BIG-IP VE version 13.0.0 HF2 EHF3 for this example. Alright, let’s get started. Open the console, go to Cloud Launcher and search for F5. Pick the version you want. Now click Launch on Compute Engine. I’m going to change the name so the VM is easier to find… For everything else, I’ll leave the defaults. And then down under firewall, if these ports aren’t already open on your network, you can open 22, which you need so you can use SSH to connect to the instance, and 8443, so you can use the BIG-IP Configuration utility—the web tool that you use to manage the BIG-IP. Now click Deploy. It takes just a few minutes to deploy. And Deployed. When you’re done, you can connect straight from the Google console. This screen cap shows SSH but if you use the browser window, you need to change the Linux username to admin in order to connect. Once done, you'll get that command line. If you choose the gcloud command line option and then run in the gcloud shell, you need to put admin@ in front of the instance name in order to connect. We like using putty so first we need to go get the external IP address of the instance. So I look at the instance and copy the external IP. Then we go into Metadata > SSH keys to confirm that the keys are there. (Added earlier), Whichever keys you want to use to connect, you should put them here. BIG-IP VE grabs these keys every minute or so, so any of the non-expired keys in this list can access the instance. If you remove keys from this list, they’ll be removed from BIG-IP and will no longer have access. You do have the option to edit the VM instance and block project-wide keys if you’d like. Because my keys are already in this list I can open Putty now, and then specify my keys in order to connect. The reason that we're using ssh to connect is that you need to set an admin password that’s used to connect to the BIG-IP Config utility. So I’m going to set the admin password here… (and again, you can do these same steps, no matter how you connect to the instance) tmsh Command is: modify auth modify auth password admin And then: save sys config to save the change. Now we can connect and log in to the BIG-IP Config utility by using https, the external IP and port 8443. Now type admin and the password we just set. Then we can proceed with licensing and provisioning BIG-IP VE. A few other notes: If you’re used to creating a self IP and VLAN, you don’t need to do that. In this single NIC deployment, those things are taken care of for you. If you want to start sending traffic, just set up your pool and virtual server the way you normally would. Just make sure if your app is using port 443, for example, that you add that firewall rule to your network or your instance. And finally, you most likely want to make your external IP address one that is static, and you can do that in the UI by choosing Networking, then External IP addresses, then Type). If you need any help, here's the Google Cloud Platform/BIG-IP VE Setup Guide and/or watch the full video. ps854Views0likes1Comment
BIG-IP LTM VE: Transfer your iRules in style with the iRule Editor
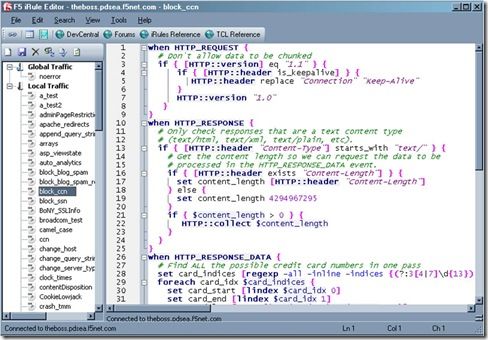
The new LTM VE has opened up the possibilities for writing, testing and deploying iRules in a big way. It’s easier than ever to get a test environment set up in which you can break things develop to your heart’s content. This is fantastic news for us iRulers that want to be doing the newest, coolest stuff without having to worry about breaking a production system. That’s all well and good, but what the heck do you do to get all of your current stuff onto your test system? There are several options, ranging from copy and paste (shudder) to actual config copies and the like, which all work fine. Assuming all you’re looking for though is to transfer over your iRules, like me, the easiest way I’ve found is to use the iRule editor’s export and import features. It makes it literally a few clicks and super easy to get back up and running in the new environment. First, log into your existing LTM system with your iRule editor (you are using the editor, right? Of course you are…just making sure). You’ll see a screen something like this (right) with a list of a bagillionty iRules on the left and their cool, color coded awesomeness on the right. You can go through and select iRules and start moving them manually, but there’s really no need. All you need to do is go up to the File –> Archive –> Export option and let it do its magic. All it’s doing is saving text files to your local system to archive off all of your iRuley goodness. Once that’s done, you can then spin up your new LTM VE and get logged in via the iRule editor over there. Connect via the iRule editor, and go to File –> Archive –> Import, shown below. Once you choose the import option you’ll start seeing your iRules popping up in the left-hand column, just like you’re used to. This will take a minute depending on how many iRules you have archived (okay, so I may have more than a few iRules in my collection…) but it’s generally pretty snappy. One important thing to note at his point, however, is that all of your iRules are bolded with an asterisk next to them. This means they are not saved in their current state on the LTM. If you exit at this point, you’ll still be iRuleless, and no one wants that. Luckily Joe thought of that when building the iRule editor, so all you need to do is select File –> Save All, and you’ll be most of the way home. I say most of the way because there will undoubtedly be some errors that you’ll need to clean up. These will be config based errors, like pools that used to exist on your old system and don’t now, etc. You can either go create the pools in the config or comment out those lines. I tend to try and keep my iRules as config agnostic as possible while testing things, so there aren’t a ton of these but some of them always crop up. The editor makes these easy to spot and fix though. The name of the iRule that’s having a problem will stay bolded and any errors in that particular code will be called out (assuming you have that feature turned on) so you can pretty quickly spot them and fix them. This entire process took me about 15 minutes, including cleaning up the code in certain iRules to at least save properly on the new system, and I have a bunch of iRules, so that’s a pretty generous estimate. It really is quick, easy and painless to get your code onto an LTM VE and get hacking coding. An added side benefit, but a cool one, is that you now have your iRules backed up locally. Not only does this mean you’re double plus sure that they won’t be lost, but it means the next time you want to deploy them somewhere, all you have to do is import from the editor. So if you haven’t yet, go download your BIG-IP LTM VE and get started. I can’t recommend it enough. Also make sure to check out some of the really handy DC content that shows you how to tweak it for more interfaces or Joe’s supremely helpful guide on how to use a single VM to run an entire client/LTM/server setup. Wicked cool stuff. Happy iRuling. #Colin1.3KViews0likes1Comment
Hourly Licensing Model – F5 delivers in AWS Marketplace
#cloud #SDAS #AWS And you can try it out for free... June 30, 2014 (The Internet) Today F5 Networks, which delivers solutions for an application world, announced it had completed jumping through the hoops necessary to offer an hourly (utility) billing model for its BIG-IP VE (Virtual Edition) in the Amazon Web Services (AWS) cloud. Not only has F5 announced availability of the industry's leading application delivery services for deployment in AWS with a utility billing model, but the offering includes a variety of options which organizations can take advantage of: Three sizes of BIG-IP VE including 25 Mbps, 200 Mbps and 1Gbps. Two BYOL (Bring Your Own License) options as well as a modular option A free 30 day trial offering with Best licensing and 200 Mbps of throughput BIG-IP VE for AWS includes not only the industry's most trusted load balancing service but also the following capabilities and Software Defined Application Services (SDAS) designed to protect and enhance application security and performance: An integrated WAF (Web Application Firewall) DDoS Protection Caching, compression and acceleration Advanced Load Balancing Algorithms including least connections and weighted round robin. Additionally, BIG-IP VE for AWS supports the use of iApps for rapid provisioning in the cloud or on-premise. iApps are application-driven service templates that encapsulate best practice configurations as determined by lengthy partnerships with leading application providers as well as hundreds of thousands of real deployments across a broad set of verticals including 94% of the Fortune 50. The availability of BIG-IP VE for AWS further supports F5 Synthesis' vision to leave no application behind, regardless of location or service requirements. Through Synthesis' Intelligent Service Orchestration, organizations can enjoy seamless licensing, deployment and management of F5 services across on-premise and cloud-based environments. The availability of BIG-IP VE for AWS extends F5 service fabric into the most popular cloud environment today, and gives organizations the ability to migrate applications to the cloud without compromising on security or performance requirements. To celebrate this most momentous occasion you can try out BIG-IP in the AWS marketplace for free (for 30 days) or receive $100 credit from AWS by activating participating products between July 1 and July 31, 2014: These offers apply to the F5 BIG-IP Virtual Edition for AWS 200Mbps Hourly (Best) through AWS Marketplace: 30 Day Free Trial Available The BIG-IP Virtual Edition is an application delivery services platform for the Amazon Web Services cloud. From traffic management and service offloading to acceleration and security, the BIG-IP Virtual Edition delivers agility - and ensures your applications are fast, secure, and available. Options include: - BIG-IP Local Traffic Manager, Global Traffic Manager, Application Acceleration Manager, Advanced Firewall Manager, Access Policy Manager, Application Security Manager, SDN Services and Advanced Routing, including support for AWS CloudHSM for cryptographic operations and key storage. AWS – Offer (Credit) Customers who activate a free trial for any participating product (that includes F5 BIG-IP) between July 1 and July 31, 2014 and use the product for a minimum of 120 hours before August 31, 2014 , will receive a $100 AWS Promotional Credit. Limit two, $100 AWS Promotional Credits per customer; one per participating software seller. . For more information: F5 Synthesis F5 Solutions Available in the AWS Marketplace F5 BIP-IP Virtual Editions481Views0likes2CommentsF5 Synthesis: Tons and Tons of (Virtual) Options
#virtualization #cloud #sdas The release of Synthesis 1.5 brings more virtual edition options to the table. Most organizations are in transit between running a traditional data centers and managing a more flexible, cloud-enabled model. Their transformation continues to follow some fairly standard phases of adoption ranging from initial virtualization efforts to automation and finally hybrid environments. Each phase of this transformation brings with it new (and additive) benefits. From simplification of network architecture to scalability and on-demand capacity to the flexibility of deployment options, the transformation is certainly one most have determined to affect upon their business and the IT organization that supports (and enables) it. Pre-requisites abound, however. After all, without the availability of virtualization platforms we may not be on this transformation train at all. Cloud had to exist, too, before we could set it upon a pedestal and call it our ultimate goal. In between there are also pre-requisites; pre-requisites that enable organizations to continue on their transformation travels from virtualization to cloud computing (relatively) uninterrupted. One of those requirements is that more than application server infrastructure support virtualization. Virtualization of network and application services is critical to enabling organizations to reach their intended goals. That means vendors like F5 must not only support virtualization, but support it broadly. After all, there are a lot of hypervisors and cloud environments out there that organizations can choose to adopt. There are also a wide variety of needs in terms of capabilities (throughput, connection capacity, etc...) that need to be available to ensure every application (no matter how big or how small) is able to take advantage of the application services they need to successfully execute on their intended purpose. F5 Synthesis High Performance Services Fabric: Virtual Options One of the tenets (or principles, if you prefer) of technologies like cloud and SDN are that they essentially abstract resources in such a way as to present a unified (commoditized, really) "fabric" on which services can be deployed. Network fabrics serve up network services and application service fabrics serve up, not unsurprisingly, application services. F5 Synthesis Services Fabric leverages a common platform to enable this abstraction. The underlying resources can come from F5 hardware (appliances or its VIPRION line of chassis), software or virtualized systems (data center hosted hypervisors or in the cloud). Supporting our own hardware is obviously pretty easy. Supporting the broad set of hypervisors and software options, however, can be a bit trickier. Not just for F5, but for any traditionally hardware-bound solution. But organizations desire - nay, they demand - the flexibility of being able to rapidly deploy more capacity for services, which implies the need for more resources. Often times these may be temporary resources, or cloud resources, and that pretty much requires a software or virtualized form factor approach. But not only does it require support for a variety of hypervisors and software platforms, it also requires different capabilities. After all, adding a new department-level application and its related services is likely to consume a far different set of resources than launch the corporate flagship application. To meet both these requirements and ensure the most flexible set of options, F5 has recently added new performance tiers and hypervisor support for its VE (virtual edition) form factor. All F5 application services are available in a VE form factor and can deployed today even if your entire Synthesis Services Fabric is built on virtual editions. The flexibility afforded by F5 Synthesis' broadest hypervisor and platform support ensures organizations can continue to transform their data centers whether the end goal is pure cloud, hybrid cloud, or just a highly virtualized and automated set of systems. Wherever organizations are today - and wherever they are ultimately going - they can rest assured F5 can support their applications' need for services, no matter how big or how small they might be. For more information on Synthesis: F5 Synthesis Site More DevCentral articles on F5 Synthesis278Views0likes0Comments
In the Cloud, It's the Little Things That Get You. Here are nine of them.
#F5 Eight things you need to consider very carefully when moving apps to the cloud. Moving to a model that utilizes the cloud is a huge proposition. You can throw some applications out there without looking back – if they have no ties to the corporate datacenter and light security requirements, for example – but most applications require quite a bit of work to make them both mobile and stable. Just connections to the database raise all sorts of questions, and most enterprise level applications require connections to DC databases. But these are all problems people are talking about. There are ways to resolve them, ugly though some may be. The problems that will get you are the ones no one is talking about. So of course, I’m happy to dive into the conversation with some things that would be keeping me awake were I still running a datacenter with a lot of interconnections and getting beat up with demands for cloudy applications. The last year has proven that cloud services WILL go down, you can’t plan like it won’t, regardless of the hype. When they do, your databases must be 100% in synch, or business will be lost. 100%. Your DNS infrastructure will need attention, possibly for the first time since you installed it. Serving up addresses from both local and cloud providers isn’t so simple. Particularly during downtimes. Security – both network and app - will have to be centralized. You can implement separate security procedures for each deployment environment, but you are only as strong as your weakest link, and your staff will have to remember which policies apply where if you go that route. Failure plans will have to be flexible. What if part of your app goes down? What if the database is down, but the web pages are fine – except for that “failed to connect to database” error? No matter what the hype says, the more places you deploy, the more likelihood that you’ll have an outage. The IT Managers’ role is to minimize that increase. After a failure, recovery plans will also need to be flexible. What if part of your app comes up before the rest? What if the database spins up, but is now out of synch with your backup or alternate database? When (not if) a security breech occurs on a cloud hosted server, how much responsibility does the cloud provider have to help you clean up? Sometimes it takes more than spinning down your server to clean up a mess, after all. If you move mission-critical data to the cloud, how are you protecting it? Contrary to the wild claims of the clouderati, your data is in a location you do not have 100% visibility into, you’re going to have to take extra steps to protect it. If you’re opening connections back to the datacenter from the cloud, how are you protecting those connections? They’re trusted server to trusted server, but “trusted” is now relative. Of course there are solutions brewing for most of these problems. Here are the ones I am aware of, I guarantee that, since I do not “read all of the Internets” each day (Lori does), I’m missing some, but it can get you started. Just include cloud in your DR plans, what will you do if service X disappears? Is the information on X available somewhere else? Can you move the app elsewhere and update DNS quickly enough? Global Server Load Balancing (GSLB) will help with this problem and others on the list – it will eliminate the DNS propagation lag at least. But beware, for many cloud vendors it is harder to do DR. Check what capabilities your provider supports. There are tools available that just don’t get their fair share of thunder, IMO – like Oracle GoldenGate – that replicate each SQL command to a remote database. These systems create a backup that exactly mirrors the original. As long as you don’t get a database modifying attack that looks valid to your security systems, these architectures and products are amazing. People generally don’t care where you host apps, as long as when they type in the URL or click on the URL, it takes them to the correct location. Global DNS and GSLB will take care of this problem for you. Get policy-based security that can be deployed anywhere, including the cloud, or less attractively (and sometimes impractically), code security into the app so the security moves with it. Application availability will have to go through another round like it did when we went distributed and then SOA. Apps will have to be developed with an eye to “is critical service X up?” where service X might well be in a completely different location from the app. If not, remedial steps will have to occur before the App can claim to be up. Or local Load Balancing can buffer you by making service X several different servers/virtuals. What goes down (hopefully) must come back up. But the same safety steps implemented in #5 will cover #6 nicely, for the most part. Database consistency checks are the big exception, do those on recovery. Negotiate this point if you can. Lots of cloud providers don’t feel the need to negotiate anything, but asking the questions will give you more information. Perhaps take your business to someone who will guarantee full cooperation in fixing your problems. If you actually move critical databases to the cloud, encrypt them. Yeah, I do know it’s expensive in processing power, but they’re outside the area you can 100% protect. So take the necessary step. Secure tunnels are your friend. Really. Don’t just open a hole in your firewall and let “trusted” servers in, because it is possible to masquerade as a trusted server. Create secure tunnels, and protect the keys. That’s it for now. The cloud has a lot of promise, but like everything else in mid hype cycle, you need to approach the soaring commentary with realistic expectations. Protect your data as if it is your personal charge, because it is. The cloud provider is not the one (or not the only one) who will be held accountable when things go awry. So use it to keep doing what you do – making your organization hum with daily business – and avoid the pitfalls where ever possible. In my next installment I’ll be trying out the new footer Lori is using, looking forward to your feedback. And yes, I did put nine in the title to test the “put an odd number list in, people love that” theory. I think y’all read my stuff because I’m hitting relatively close to the mark, but we’ll see now, won’t we?201Views0likes0CommentsDNS Architecture in the 21st Century
It is amazing if you stop and think about it, how much we utilize DNS services, and how little we think about them. Every organization out there is running DNS, and yet there is not a ton of traction in making certain your DNS implementation is the best it can be. Oh sure, we set up a redundant pair of DNS servers, and some of us (though certainly not all of us) have patched BIND to avoid major vulnerabilities. But have you really looked at how DNS is configured and what you’ll need to keep your DNS moving along? If you’re looking close at IPv6 or DNSSEC, chances are that you have. If you’re not looking into either of these, you probably aren’t even aware that ISC – the non-profit responsible for BIND – is working on a new version. Or that great companies like Infoblox (fair disclosure, they’re an F5 partner) are out there trying to make DNS more manageable. With the move toward cloud computing and the need to keep multiple cloud providers available (generally so your app doesn’t go offline when a cloud provider does, but at a minimum for a negotiation tool), and the increasingly virtualized nature of our application deployments, DNS is taking on a new importance. In particular, distributed DNS is taking on a new importance. What a company with three datacenters and two cloud providers must do today, only ISPs and a few very large organizations did ten years ago. And that complexity shows no signs of slacking. While the technology that is required to operate in a multiple datacenter (whether those datacenters are in the cloud or on your premise) environment is available today, as I alluded to above, most of us haven’t been paying attention. No surprise with the number of other issues on our plates, eh? So here’s a quick little primer to give you some ideas to start with when you realize you need to change your DNS architecture. It is not all-inclusive, the point is to give you ideas you can pursue to get started, not teach you all that some of the experts I spent part of last week with could offer. In a massively distributed environment, DNS will have to direct users to the correct location – which may not be static (Lori tells me the term for this is “hyper-hybrid”) In a IPv6/IPv4 world, DNS will have to serve up both types of addresses, depending upon the requestor Increasingly, DNSSEC will be a requirement to play in the global naming game. While most orgs will go there with dragging feet, they will still go The failure of a cloud, or removal of a cloud from the list of options for an app (as elasticity contracts) will require dynamic changes in DNS. Addition will follow the same rules Multiple DNS servers in multiple locations will have to remain synched to cover a single domain. So the question is where do you begin if you’re like so many people and vaguely looked into DNSSEC or DNS for IPv6, but haven’t really stayed up on the topic. That’s a good question. I was lucky enough to get two days worth of firehose from a ton of experts – from developers to engineers configuring modern DNS and even a couple of project managers on DNS projects. I’ll try to distill some of that data out for you. Where it is clearer to use a concrete example or specific terminology, as almost always that example will be of my employer or a partner. From my perspective it is best to stick to examples I know best, and from yours, simply call your vendor and ask if they have similar functionality. Massively distributed is tough if you are coming from a traditional DNS environment, because DNS alone doesn’t do it. DNS load balancing helps, but so does the concept of a Wide IP. That’s an IP that is flexible on the back end, but static on the front end. Just like when load balancing you have a single IP that directs users to multiple servers, a Wide IP is a single IP address that directs people to multiple locations. A Wide IP is a nice abstraction to actively load balance not just between servers but between sites. It also allows DNS to be simplified when dealing with those multiple sites because it can route to the most appropriate instance of an application. Today most appropriate is generally defined by geographically closest, but in some cases it can include things like “send our high-value customers to a different datacenter”. There are a ton of other issues with this type of distribution, not the least of which is database integrity and primary sourcing, but I’m going to focus on the DNS bit today, just remember that DNS is a tool to get users to your systems like a map is a tool to get customers to your business. In the end, you still have to build the destination out. DNS that supports IPv4 and IPv6 both will be mandatory for the foreseeable future, as new devices come online with IPv6 and old devices persist with IPv4. There are several ways to tackle this issue, from the obvious “leave IPv4 running and implement v6 DNS” to the less common “implement a solution that serves up both”. DNSSEC is another tough one. It adds complexity to what has always been a super-simplistic system. But it protects your corporate identity from those who would try to abuse it. That makes DNSSEC inevitable, IMO. Risk management wins over “it’s complex” almost every time. There are plenty of DNSSEC solutions out there, but at this time DNSSEC implementations do not run BIND. The update ISC is working on might change that, we’ll have to see. The ability to change what’s behind a DNS name dynamically is naturally greatly assisted by the aforementioned Wide IPs. By giving a constant IP that has multiple variable IPs behind it, adding or removing those behind the Wide IP does not suffer the latency that DNS propagation requires. Elasticity of servers servicing a given DNS name becomes real simply by the existence of Wide IPs. Keeping DNS servers synched can be painful in a dynamic environment. But if the dynamism is not in DNS address responses, but rather behind Wide IPs, this issue goes away also. The DNS servers will have the same set of Name/address pairs that require changes only when new applications are deployed (servers is the norm for local DNS, but for Wide-IP based DNS, servers can come and go behind the DNS service with only insertion into local DNS, while a new application might require a new Wide-IP and configuration behind it). Okay, this got long really quickly. I’m going to insert an image or two so that there’s a graphical depiction of what I’m talking about, then I’m going to cut it short. There’s a lot more to say, but don’t want to bore you by putting it all in a single blog. You’ll hear from me again on this topic though, guaranteed. Related Articles and Blogs F5 Friday: Infoblox and F5 Do DNS and Global Load Balancing Right. How to Have Your (VDI) Cake and Deliver it Too F5 BIG-IP Enhances VMware View 5.0 on FlexPod Let me tell you Where To Go. Carrier Grade DNS: Not your Parents DNS Audio White Paper - High-Performance DNS Services in BIG-IP ... Enhanced DNS Services: For Administrators, Managers and Marketers The End of DNS As We Know It DNS is Like Your Mom F5 Video: DNS Express—DNS Die Another Day340Views0likes0CommentsOn the Trading Floor and in the QA Lab
#fsi problems are very public, but provide warning messages for all enterprises. The recent troubles in High Frequency Trading (HFT) involving problems on the NASDAQ over the debut of Facebook, the Knight Trading $400 Million USD loss among others are a clear warning bell to High Frequency Trading organizations. The warning comes in two parts: “Testing is not optional”, and “Police yourselves or you will be policed”. Systems glitches happen in every industry, we’ve all been victims of them, but Knight in particular has been held up as an example of rushing to market and causing financial harm. Not only did the investors in Knight itself lose most of their investment (between the impact on the stock price and the dilution of shares their big-bank bailout entailed, it is estimated that their investors lost 80% or more in a couple of weeks), but when the price of a stock – particularly a big-name stock, which the hundred they were overtrading mostly were – fluctuates dramatically, it creates winners and losers in the market. For every person that bought cheap and sold high, there was a seller at the low end and a buyer at the high end. Regulatory agencies and a collection of university professors are reportedly looking into an ISO-9000 style quality control system for the HFT market. One more major glitch could be all it takes to send them to the drafting table, so it is time for the industry itself to band together and place controls, or allow others to dictate controls. Quality assurance in every highly competitive industry has this problem. They are a cost center, and while everyone wants a quality product, many are annoyed by the “interference” QA brings into the software development process. This can be worse in a highly complex network like HFT or a large multi-national requires, because replicating the network for QA purposes can be a daunting project. This is somewhat less relevant in smaller organizations, but certainly there are mid-sized companies with networks every bit as complex as large multi-nationals. Luckily, we have reached a point in time where a QA environment can be quickly configured and reconfigured, where testing is more of a focus on finding quality problems with the software than on configuring the environment – running cables, etc – that has traditionally cost QA for networked applications a lot of time or a lot of money maintaining a full copy of the production network. From this point forward, I will mention F5 products by name. Please feel free to insert your favorite vendors’ name if they have a comparable product. F5 is my employer, so I know what our gears’ capabilities are, competitors that is less true for, so call your sales folks and ask them if they support the functionality described. Wouldn’t hurt to do that with F5 either. Our sales people know a ton, and can clarify anything that isn’t clear in this blog. In the 21st century, testing and Virtualization go hand-in-hand. There are a couple of different forms of network virtualization that can help with testing, depending upon the needs of your testing team and your organization. I refer to them as QA testing and performance testing, think of them as “low throughput testing” and “high throughput testing”. If you’re not testing performance, you don’t need to see a jillion connections a second, but you do need to see all of the things the application does, and make certain they match requirements (more often design, but that’s a different blog post concerning what happens if the design doesn’t adequately address requirements and testing is off of design…). Quality Assurance For low throughput testing, virtualization has been the king for a good long while, with only cloud even pretending to challenge the benefits of a virtualized environment. Since “cloud” in this case is simply IaaS running VMs, I see no difference for QA purposes. This example could be in the cloud or on your desktop in VMs. Dropping a Virtual Application Delivery Controller (vADC) into the VM environment will provide provisioning of networking objects in the same manner as is done in the production network. This is very useful for testing multiple-instance applications for friendliness. It doesn’t take much of a mistake to turn the database into the bottleneck in a multiple-instance web application. Really. I’ve seen it happen. QA testing can see this type of behavior without the throughput of a production network, if the network is designed to handle load balanced copies of the application. It is also very useful for security screening, assuming the vADC supports a Web Application Firewall (WAF) like the BIG-IP with its Application Security Manager. While testing security through a WAF is useful, the power of the WAF really comes into play when a security flaw is discovered in QA testing. Many times, that flaw can be compensated for with a WAF, and having one on the QA network allows staff to test with and without the WAF. Should the WAF provide cover for the vulnerability, an informed decision can then be made about whether the application deployment must be delayed for a bug fix, or if the WAF will be allowed to handle protection of that particular vulnerability until the next scheduled update. In many cases, this saves both time and money. In cases of heavy backend transport impacting the performance of web applications – like mirroring database calls to a remote datacenter – the use of a WAN Optimization manager can be evaluated in test to see if it helps performance without making changes to the production network. Testing network object configurations is easier too. If the test environment is set up to mirror the production network, the only difference being that testing is 100% virtualized, then the exact network object – load balancing, WAN optimization, Application Acceleration, Security, and WAF can all be configured in QA Test exactly as they will be configured in production. This allows for thorough testing of the entire infrastructure, not just the application being deployed. Performance Testing For high-throughput testing, the commodity hardware that runs VMs can be a limiting factor in the sense that the throughput in test needs to match the expected usage of the application at peak times. For these scenarios, organizations with high-volume, mission-critical applications to test can run the same exact testing scenario using a hardware chassis capable of multi-tenancy. As always, I work for F5 so my experience is best couched in F5 terms. Our VIPRION systems are capable of running multiple different BIG-IP instances per blade. That means that in test, the exact same hardware that will be used in production can be used for performance evaluation. Everything said above about QA testing – WAF, Application Acceleration, testing for bottlenecks, all apply. The biggest difference is that the tests are on a physical machine, which might make testing to the cloud more difficult as the machine cannot be displaced to the cloud environment. To resolve this particular issue, the hybrid model can be adopted. VIPRION on the datacenter side and BIG-IP VE on the cloud side, in the case of F5. Utilizing management tools like the iApps Analytics built in to F5 Enterprise Manager (EM) allow testers to see which portion of the architecture is limiting performance, and save man-hours searching out problems. It’s Still About The App and the Culture In the end, the primary point of testing is to safeguard against coding errors that would cause real pain to the organization and get them fixed before the application is turned live. The inclusion of network resources in testing is a reflection of the growing complexity many web based applications are experiencing in supporting infrastructure. Just as you wouldn’t test a mainframe app on a PC, testing a networked app outside of the target environment is not conclusive. But the story at Knight trading does not appear to be one about testing, but rather culture. In a rush to meet an artificial deadline, they appear to have cut corners and rushed changes in the night before. You can’t fix problems with testing if you aren’t testing. Many IT shops need to take that to heart. The testers I have worked with over the years are astounding folks with a lot of smarts, but all suffer from the problem that their organization doesn’t value testing at the level it does other IT functions. Dedicated testing time is often in short order and the first thing to go when deadlines slip. Quite often testers are developers who have the added responsibility of testing. But many of us have said over the years and will continue to say… Testing your own code is not a way to find bugs. Don’t you think – really think – that if a developer thinks of it in testing, he/she probably thought of it during development? While those problems not thought of in development can certainly be caught, a fresh set of eyes setting up tests outside the context of developer assumptions is always a good idea. And Yeah, it’s happened to me Early in my career, I was called upon to make a change to a software package used by some of the largest banks in the US. I ran the change out in a couple of hours, I tested it, there was pressure to get it out the door so the rockstars in our testing department didn’t even know about the change, and we delivered it electronically to our largest banking customer – who was one of the orgs demanding the change. In their environment, the change over-wrote the database our application used. Literally destroyed a years’ worth of sensitive data. Thankfully, they had followed our advice and backed up the database first. While they were restoring, I pawed through the effected change line-by-line and found that the error destroying their database was occurring in my code, just not doing any real harm (it was writing over a different file on my system), so I didn’t notice it. Testing would have saved all of us a ton of pain because it would have been putting the app in a whole new environment. But this was a change “that they’re demanding NOW!” The bank in question lost the better part of a day restoring things to normal, and my company took an integrity hit with several major customers. I learned then that a few hours of testing of a change that took a few hours to write is worth the investment, no matter how much pressure there is to deliver. Since then, I have definitely pushed to have a test phase with individuals not involved with development running the app. And of course, the more urgent the change, the more I want at least one person to install and test outside of my dev machine. And you should too. Related Articles and Blogs There is more to it than performance. DEFCON 20 Highlights How to Develop Next-Gen Project Managers220Views0likes0CommentsLet me tell you Where To Go.
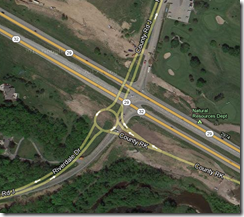
One thing in life, whether you are using a Garmin to go to a friend’s party or planning your career, you need to know where you’re going. Failure to have a destination in mind makes it very difficult to get directions. Even when you know where you’re going, you will have a terrible time getting there if your directions are bad. Take, for example, using a GPS to navigate between when they do major road construction and when you next update your GPS device’s maps. On a road by my house, I can actually drive down the road and be told that I’m on the highway 100 feet (30 meters) distant. Because I haven’t updated my device since they built this new road, it maps to the nearest one it can find going in the same direction. It is misinformed. And, much like the accuracy of a GPS, we take DNS for granted until it goes horribly wrong. Unfortunately, with both you can be completely lost in the wild before you figure out that something is wrong. The number of ways that DNS can go wrong is limited – it is a pretty simple system – but when it does, there is no way to get where you need to go. Just like when construction dead-ends a road. Like a road not too far from my house. Notice in the attached screenshot taken from Google Maps, how the satellite data doesn’t match the road data. The roads pictured by the satellite actually intersect. The ones pictured in roadway data do not. That is because they did intersect until about eight months ago. Now the roadway data is accurate, and one road has a roundabout, while the other passes over it. As you can plainly see, a GPS is going to tell you “go up here and turn right on road X”, when in reality it is not possible to do that any more. You don’t want your DNS doing the same thing. Really don’t. There are a couple of issues that could make your DNS either fail to respond or misdirect people. I’ll probably talk about them off-n-on over the next few months, because that’s where my head is at the moment, but we’ll discuss the two obvious ones today, just to keep this blog to blog length. First is failure to respond – either because it is overloaded, or down, or whatever. This one is easy to resolve with redundancy and load balancing. Add in Global Load Balancing, and you can distribute traffic between datacenters, internal clouds, external clouds, whatever, assuming you have the right gear for the job. But if you’re a single datacenter shop, simple redundancy is pretty straight-forward, and the only problem that might compel you to greater measures is a DDoS attack. While a risk, as a single datacenter shop, you’re not likely to attract the attention of crowds that want to participate in DDoS unless you’re in a very controversial market space. So make sure you have redundancy in DNS servers, and test them. Amazing the amount of backup/disaster recovery infrastructure that doesn’t have a regular, formalized testing plan. It does you no good to have it in place if it doesn’t work when you need it. The other is misdirection. The whole point of DNS cache poisoning is to allow someone to masquerade as you. wget can copy the look-n-feel of your website, cache poisoning (or some other as-yet-unutilized DNS vector) can redirect your users to the attacker. They typed in your name, they got a page that looks like your page, but any information they enter goes to someone else. Including passwords and credit card numbers. Scary stuff. So DNS SEC is pretty much required. It protects DNS against known attacks, and against a ton of unexplored vectors, by utilizing authorization and encryption. Yeah, that’s a horrible overstatement, but it works for a blog aimed at IT staff as opposed to DNS uber-specialists. So implement DNS SEC, but understand that it takes CPU cycles on DNS servers – security is never free – so if your DNS system is anywhere near capacity, it’s time to upgrade that 80286 to something with a little more zing. It is a tribute to DNS that many BIND servers are running on ancient hardware, because they can, but it doesn’t hurt any to refresh the hardware and get some more cycles out of DNS. In the real world, you would not use a GPS system that might send you to the wrong place (I shut mine down when in downtown Cincinnati because it is inaccurate, for example), and you wouldn’t use one that a crook could intercept the signal from and send you to a location of his choosing for a mugging rather than to your chosen destination… So don’t use a DNS that both of these things are possible for. Reports indicate that there are still many, many out of date DNS systems running out there. upgrade, implement DNS SEC, and implement redundancy (if you haven’t already, most DNS servers seem to be set up in pairs pretty well) or DNS load balancing. Let your customers know that you’re doing it more reliable and secure – for them. And worry about one less thing while you’re grilling out over the weekend. After all, while all of our systems rely on DNS, you have to admit it gets very little of our attention… Unless it breaks. Make yours more resilient, so you can continue to give it very little attention.208Views0likes0CommentsNetworking Options with LTM VE
If you haven’t yet downloaded the BIG-IP LTM VE trial, I highly suggest you do. It is a fully-functional LTM, rate-limited to 1Mbps throughput. If you’re not familiar with virtualized environments, hopefully this blog will fill in some blanks for how to get started on the network front. Getting Started Before downloading your VE image, you need to choose what virtualization environment you’re installing into. The supported options in the type 1 hypervisor are VMWare ESX version 4 and ESXi version 4. For the type 2 hypervisor (requiring a host OS such as linux or Microsoft Windows) the supported option is VMWare Workstation 7, which offers a 30-day free trial that I recommend you give a shot, or for those with experience on VMWare player, that also will suffice if you are at version 3. Note, however, that VMWare player is not supported by F5. Hypervisor Type 2 Options – VMWare Workstation & Player In LTM VE, you have three interfaces—one managment and two data (1.1 & 1.2). On the Workstation/Player products, you specify in the virtual appliance settings how the interfaces will connect. You can specify any of the following interface types: Bridged – Allows access through your physical NIC to participate in the local area network. NAT – Allows access through your physical NIC, but utilizes your machines IP and translates for VM traffic. Host Only – Networks are defined locally in virtual nics that have no significance outside your locally defined virtualization environment. With the Workstation product, there is a Virtual Network Editor application where you can define the networks your virtual appliances will use, as well as setting dhcp options, etc. The player doesn’t have this application, and doesn’t give the custom option in the GUI interface, but the settings can be configured manually in the appliance configuration files (shown below). To get started quickly, I bridge the management interface so I can download directly from the management shell. I use a host-only interface assigned at layer3 on both my laptop and the VE image so I can run test traffic against my iRules for syntax and functional checking. I have a virtual appliance on a layer2 network (layer3 for VE and the server appliance, but there isn’t a layer3 interface for vmware itself) between it and VE so I can pass traffic from my laptop through VE to the vm server and back as necessary for testing. A diagram detailing this is shown below to the left of the matching configuration options set in the virtual appliance files. # MGMT NETWORK ethernet0.present = "true" ethernet0.virtualDev = "vlance" ethernet0.addressType = "generated" ethernet0.connectionType = "bridged" ethernet0.startConnected = "true" # INT 1.1 ethernet1.present = "true" ethernet1.virtualDev = "e1000" ethernet1.addressType = "generated" ethernet1.connectionType = "custom" ethernet1.startConnected = "true" ethernet1.vnet = "VMnet1" # INT 1.2 ethernet2.present = "true" ethernet2.virtualDev = "e1000" ethernet2.addressType = "generated" ethernet2.connectionType = "custom" ethernet2.startConnected = "true" ethernet2.vnet = "VMnet2" I think in order to take advantage of route domains on the workstation product, you’d need a couple virtual appliances in different vmnets that are only layer2 aware. Still, there are plenty of possibilities with apache vserver configurations if you have the memory to spin up a virtual appliance in addition to the BIG-IP LTM VE. Hypervisor Type 1 Options – VMWare ESX 4/ ESXi 4 In ESX/ESXi, it’s both more complicated and more simple. Yeah, I said that. The assigning of interfaces is trivial, as there really isn’t a concept at the virtual appliance level of bridging, natting, or host only. The ESXi platform has an underlying virtual switching infrastructure where all the science of networking is configured. You can teem your nics and run all your vlans across them, or you can segment by function. When deploying the .ova image to ESXi, the only interesting questions are what datastore you will use to house your VE image and what networks to apply to the VE interfaces. Given that you cannot create them on the fly, you’ll need to do some prep work to make sure your interfaces are already defined before deploying the image. Questions? We turned on an LTM VE specific forum today should you have any questions regarding installation, network configuration, VE options, etc. We hope you get as much use and enjoyment out of this release as we do.723Views0likes3Comments